Remote Procedure Call (RPC) is a protocol where one program can invoke service, function or a subroutine from a program located in another computer on a network without understanding the network’s details. Remote Procedure call – RPC makes remote calls just as simple a local calls.
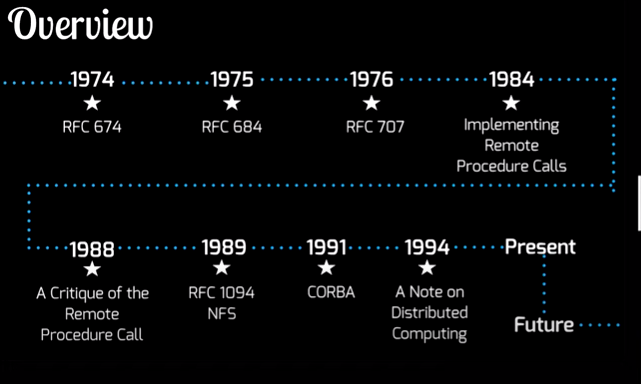
Introduced Procedure call paradigm PCP, an attempt to define a mechanism for resource sharing across all 70 nodes on the Internet.
1975 – RFC 684 Criticisms of the previous RFC 674
Local and remote calls have different cost profiles, meaning that a local call will always return the control flow to the invoker, but remote calls always don’t work like this.
Remote calls can be delayed or never returned, meaning local calls have some fixed latency profile, but remote calls have unpredictable latency.
In this RFC, they proposed Asynchronous message passing instead of RPC, which is a better model because it makes the passing of messages explicit. In this way, the local execution will not wait for the response of the remote call.
1976 RFC 707 A high-level framework for Network-based Resource sharing
Generalization to functions – they proposed generalizing the TELNET and FTP call and response model to functions from application-specific grammar and having one port for all protocols. They questioned why those couldn’t be just a function call and proposed implementing them as different RPC functions.
Even though they proposed this, they were still critiques of the Control flow. Calling and waiting for a response is terrible because it has to wait to perform an action to be finished.
1984 Implementing Remote Procedure Calls
Paper by Andrew D. Birrell and Bruce Jay Nelson from Xerox Research center. This is defined as the standard for the RPC system
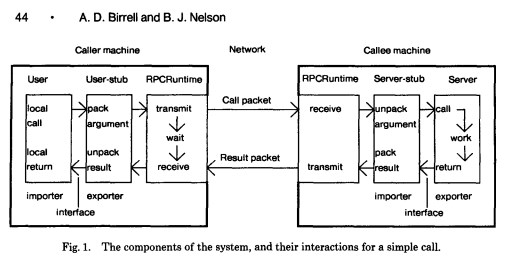
Later this became the Sun Microsystems Sun RPC. In 1988 Sun Microsystems Remote Procedure Call Protocol Specification was published in RFC 1057 – the first commercial-grade RPC
1988 A critique of RPC paradigm
They criticized that the RPC system pointing that chances of this working is less because of various reasons.
Some of the reasons they highlighted are how it would handle failures, partial failures, and there are no reliable failure detectors,
unsolvable problems like two generals problem in an asynchronous distributed system.
Because RPC is not solving the problems related to the network and its failures – there are no good failure detectors.
Because of these issues, they argued that the RPC is not the correct direction to go forward.

1989 RFC 1094 Network File System (NFS) protocol specification by Sun Microsystem
NFS is trying to use the existing local file system’s API to use a remote file system. Sun NFS is the first major distributed file system that gained popularity and adhered to the UNIX file system API.
They introduced two mounting methods:
Soft Mounting – Introduced new error codes for distributed failures that existing UNIX applications could not handle.
Hard mounting – Operations would block until they could be completed successfully. For example, you run ~ls command, and your terminal gets hanged, and you have to wait for things to return. Or you have to kill it because you are in some IO blocking state.
1991 CORBA Common Object Request Broker Architecture
It supported cross-language, cross address space interoperability for object-oriented programming.
Interface definition language (IDL) generates stubs for remote objects and maps between different primitive types.
“It’s just a mapping problem” remote to local exception mapping, remote to the local method invocation.
But this was challenged by an article in 1994 from Sun microsystems called “A note on distributed computing.”
It challenges CORBA, and it challenges everything. They said that “it is the thesis of this note that this unified view of objects is mistaken.”
He says this for few reasons:
- Latency is a problem – Performance analysis is non-trivial, and one design is not always going to be the suitable design.
- Memory access – how do we deal with the problems of pointers and references? Once moved, they are no longer valid unless we use distributed shared memory.
- Partial failure – Failures are detectable in the local environment and result in a “return of control.” In distributed computing, this isn’t true.
The main question they ask is that should we treat all objects as local OR treat all objects as remote?
Why treating all objects as remote is bad?
This approach would also defeat the overall purpose of unifying the object model. The real reason for attempting such unification is to make distributed computing more like local computing and thus make distributed computing easier. This second approach to unifying the models makes local computing as complex as distributed computing.
Present – Re-emergence of RPC frameworks
Whatever the reasons that modern applications are mostly distributed in nature. Like microservices etc.
Because of this, we can see RPC re-emerges back in the form of RPC frameworks.
Because JSON, SOAP, string type API calls are expensive, we need to find an efficient and compressed framework to communicate with remote services written in different languages.
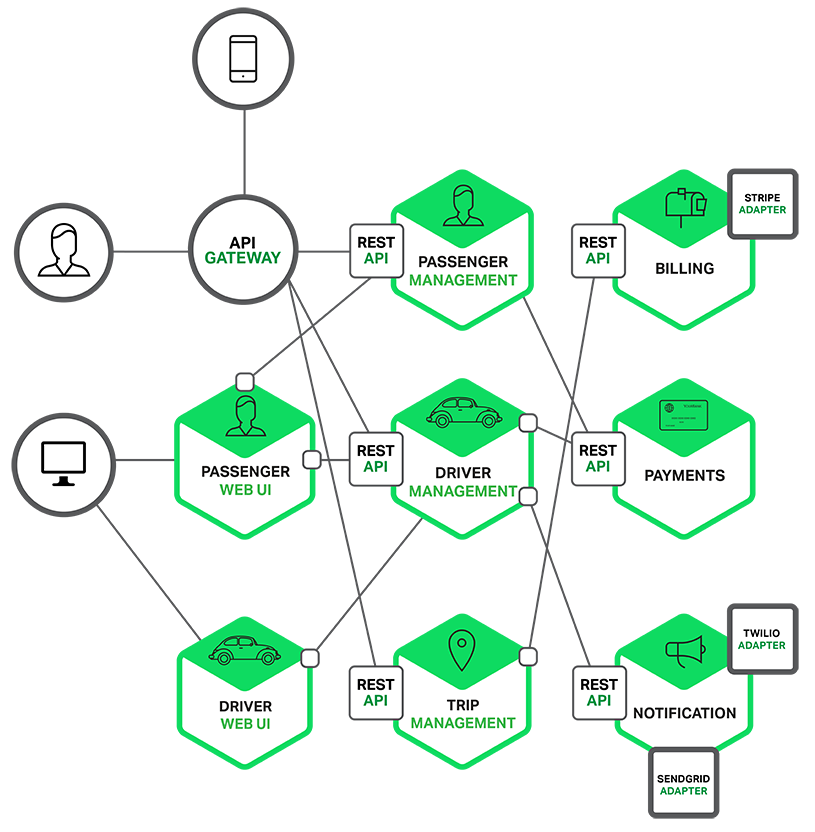
Microservices interaction using REST APIs
How do we avoid text-based APIs like REST to build services today?
Finagle: A protocol-agnostic RPC System
Finagle is a protocol-agnostic, asynchronous RPC system for the JVM that makes it easy to build robust clients and servers in Java, Scala, or any JVM-hosted language.
It has Interface Definition Language, which is Thrift. it helps maps with different data types that are based on the idea that came from CORBA.
It solves the problem of dealing with memory addresses, service discovery, etc. They applied promises – this solved the control flow problem. So, this way, we don’t have to sit there and wait for the remote service to respond. Fire a bunch of requests and action on promises.
Request/response gives clear differentiation between what’s local and what’s remote. Also, it provides other features like time-outs, retries.
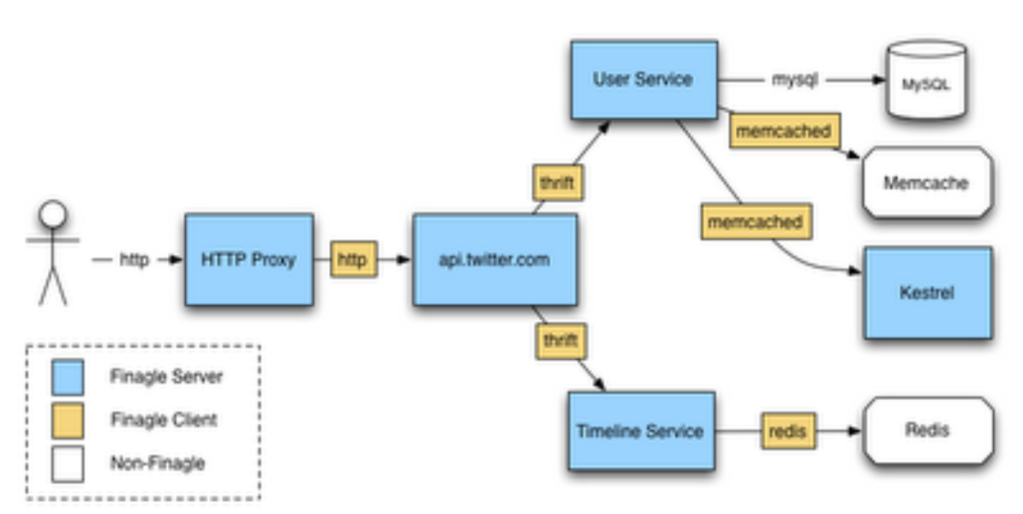
Finagle-based architecture in Twitter.
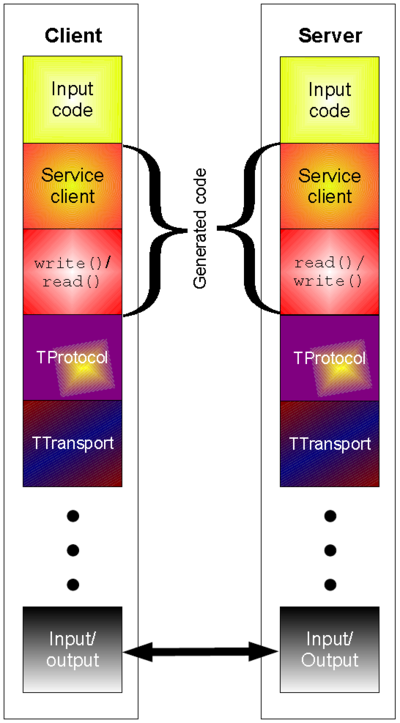
Thrift
Thrift is an RPC framework and was developed at Facebook for cross-language services development. Now it is open-sourced as an Apache project. It has the below characteristics:
-Lightweight
-Language-independent
-Has a code generation mechanism that provides a clean abstraction for data transport
data serialization and application-level processing
The thrift code generation tool allows developers to build RPC clients and servers by defining the data types and service interfaces in a simple definition file.
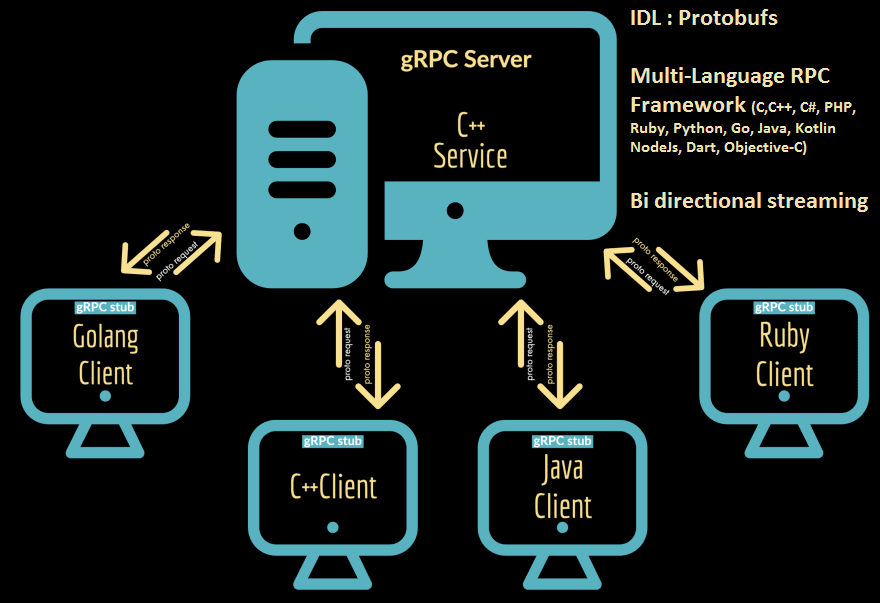
GRPC
GRPC is an RPC system initially developed at Google in 2015 as the next generation of the RPC. It is based on protocol buffers (proto-buff) as the interface description language and uses HTTP2 transport.
GRPC has more language support compared to Thrift and is not based on JVM compared to Finagle
It supports bi-directional streaming, has a good service discovery system, and it knows where machines live.
So, have we solved the RPC problem?
Modern RPC frameworks don’t provide unified modeling, and they never tried to. So are they RPC frameworks in the sense of what we started with?
It solves the problem of getting the things on the wire, but it doesn’t solve what should happen if it fails. How long should it wait to fail? Should I retry? Do we need something else?

Future
Lasp
Lasp is a Distributed Deterministic Programming System developed using Erlang. Lasp is composed of a group of Erlang libraries that work together to provide services for the development of planetary-scale applications. Lasp programs will expect to behave the same whether executed on one computer or distributed across many.
Spores: A Type-Based Foundation for Closures in the Age of Concurrency and Distribution
- Spores are small units of possibly mobile functional behavior.
- Serializable closures with capture controlled by the type system (Scala)
- Dual to Actor Systems like Erlang. Actors exchange data with async messaging; spores are stateless processes that pass functions around with asynchronous messages.
Reference: Based on a talk by Christopher Meiklejohn and Caitie McCaffrey at Code Mesh 2016

